
- ¿Qué es una base de datos? - noviembre 7, 2020
- ¿Es la programación una profesión para ti? - septiembre 3, 2020
- Temporada 2020-2021 - julio 15, 2020
Introducción
En un artículo previo te he explicado como dar los primeros pasos con Hadoop, su instalación y su configuración junto con la información necesaria para que entiendas para qué se utiliza y cual es su objetivo. Si no lo has leído, aquí tienes el enlace: ¡Primeros pasos con Hadoop!
Con este artículo el objetivo que tengo es que seas capaz de realizar tu primer desarrollo utilizando Hadoop, ¡empecemos!
Descripción del ejemplo
El software que vas a desarrollar utiliza las operaciones de Map y Reduce de Hadoop para realizar un conteo de ventas de un producto específico por provincias. El objetivo de este conteo es saber que provincias tienen más ventas y poder potenciar así la venta de productos en aquellas provincias en las que el número es menor.
Los datos que extraigas del ejemplo pueden ser utilizados posteriormente para analizar el ratio de personas trabajando y ventas, ventas medias basadas en el número de habitantes de la provincia, etc.
El desarrollo que vas a realizar utilizará una serie de ficheros CSV extraídos de la base de datos de la empresa que contienen cada venta realizada y la información asociada a la misma. Los ficheros CSV se encuentran cargados en Hadoop, separados por año.
Preparación entorno
Para el desarrollo se ha utilizado el IDE Eclipse Mars.2; puedes utilizar cualquier versión moderna de Eclipse, yo te recomiendo esta porque es la que yo he utilizado con la versión 2.7.1 de Hadoop y funciona todo a la perfección.
Lo primero que debes hacer es crear el proyecto Java sobre el que desarrollarás el código fuente que utilizará las operaciones Map y Reduce de Hadoop; en el cuadro de diálogo especificaremos la versión del JRE a utilizar, tal y como te muestro en la imagen siguiente:
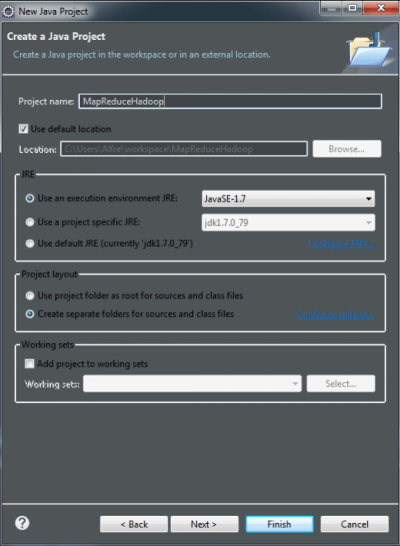
Una vez tienes creado el proyecto, el siguiente paso es que añadas las librerías externas de Hadoop que son necesarias para el desarrollo y posterior ejecución del mismo. La imagen a continuación te muestra las que yo he añadido para poder desarrollar este ejemplo:
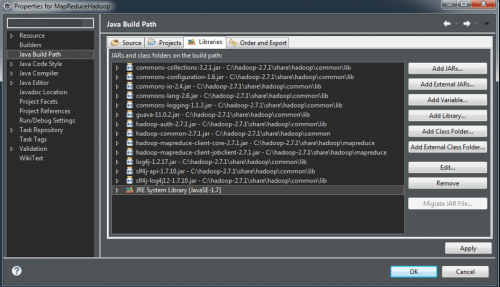
Codificación
Tras especificar las librerías, el siguiente paso que tienes que hacer es añadir la clase Java que contendrá el código fuente del desarrollo.
En la clase Main vas a especificar las clases que se encargarán de realizar el Map y el Reduce. Estas clases se encuentran parametrizadas y recibirán la información del directorio donde se encuentran los ficheros CSV a procesar y el directorio donde se almacenará el fichero con la salida de la ejecución.
El código fuente de la clase Main es el siguiente:

La clase Map se encarga de realizar el mapeo de todos los ficheros; procesando la información que contienen según los criterios especificados.
En esta clase es donde se encuentra la lógica de funcionamiento del desarrollo. El código referente al producto sobre el que se realizará el conteo ocupa el lugar 4 dentro de cada entrada del fichero CSV; si el código de dicho producto es «1134» el registro será marcado para insertarlo. La posición 9 del fichero es la posición que ocupa la provincia; que es el campo que se almacenará en el mapeo realizado.
En la imagen a continuación puedes ver el código fuente de la clase Map:
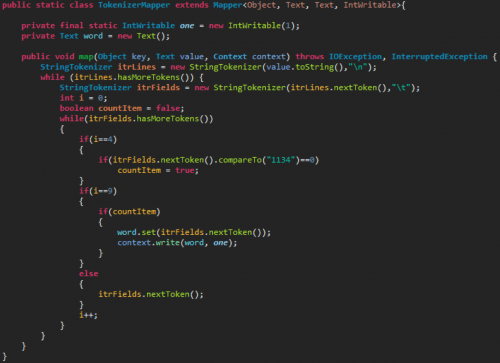
En la clase Reducer se realizará la operación de reducir el resultado de todos los mapeos realizados por la clase Map. El código fuente es el siguiente:
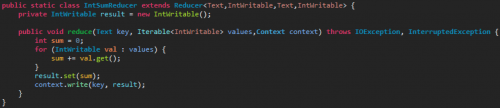
El último paso del desarrollo es la exportación del código a fichero «jar». Para ello exportaremos como fichero JAR ejecutable, tal y como se muestra en la siguiente imagen:
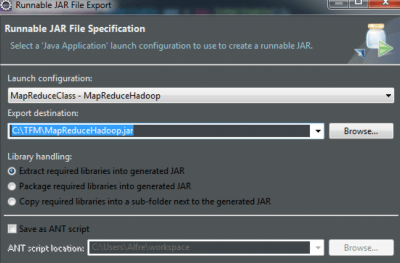
El siguiente paso es especificar el lugar dónde lo exportaremos y la configuración con la que lo exportaremos, tal y como se muestra en la siguiente imagen:
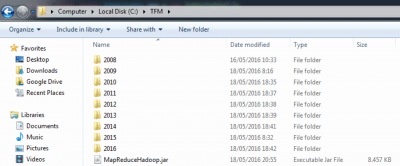
Como puede observarse en la siguiente imagen, el fichero ha sido exportado al directorio C:\TFM:
Ejecución
En la prueba siguiente van a contabilizarse el número de productos específicos por provincia de todo el año 2015.
Para ello, se ejecuta el siguiente comando, mediante el cual, se especifica la carpeta del sistema de fichero donde se encuentran los ficheros del año 2015 y el directorio donde almacenaremos la salida del procesamiento de los mismos:

Una vez acabada la ejecución, se puede ver en pantalla toda la información referente a dicha ejecución:
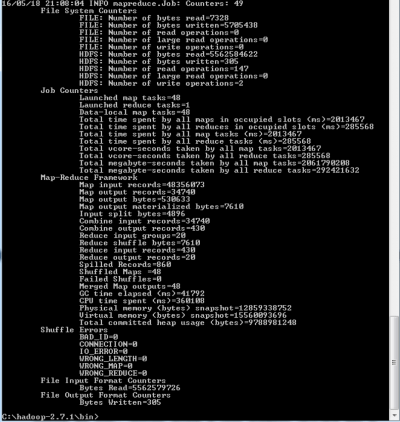
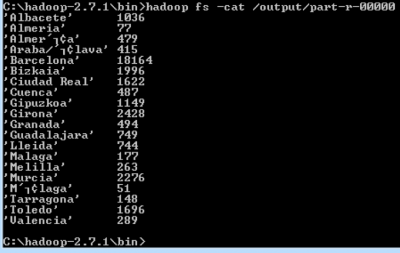
El fichero de salida de la ejecución puedes consultarlo mediante el comando «cat» de Hadoop, obteniendo la siguiente información:
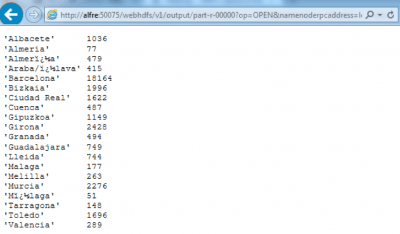
También puedes consultar la información desde el GUI del Datanode. En la imagen siguiente se muestra el resultado en el navegador:
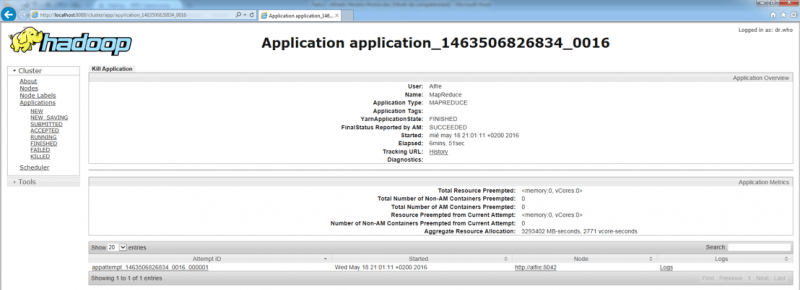
En el GUI del ResourceManager se puede consultar la información del proceso que acabamos de ejecutar; también es posible consultar todos los procesos que hayamos ejecutado, ya que guarda el histórico de los mismos. En la información del proceso se puede comprobar el resultado de la ejecución, el tiempo que ha tardado, el tipo de aplicación ejecutada y mucha más información accesible desde los enlaces a logs e históricos. En la imagen siguiente se muestra la información de la ejecución que se acaba de realizar:
Conclusiones
¡Conseguido! ¡Has realizado tu primer desarrollo utilizando las operaciones Map y Reduce de Hadoop!
Estoy seguro que te has quedado sorprendido con la velocidad de procesamiento de datos que tiene. Es una herramienta que es capaz de analizar una cantidad muy grande de datos en un tiempo ridículo si lo comparamos con lo que tardarías en analizarlos utilizando un desarrollo de software convencional.
Has podido observar también que se trata de un tecnología muy sencilla de utilizar…te animo a pensar sobre posibles usos que podrías darles en los proyectos con los que trabajas habitualmente y te hagas la siguiente pregunta:
¿Cuántos proyectos podrían mejorarse utilizando esta tecnología?