

- ¿Qué es una base de datos? - noviembre 7, 2020
- ¿Es la programación una profesión para ti? - septiembre 3, 2020
- Temporada 2020-2021 - julio 15, 2020
Introducción
No hay nada más valioso para todas las empresas que los datos, en ellos residen todos sus procesos de negocio junto con toda la información de los clientes que tienen.
Existen procesos de descubrimiento de información en las bases de datos, que permiten a las empresas extraer nuevos datos del conjunto de datos que tienen almacenados. Obviamente, mediante la utilización del Big Data y la digitalización de las empresas, éstas, almacenan cada vez más variedad de datos y variedad de tipos de datos, es por ello que, en estos momentos las empresas están empezando a utilizar técnicas de descrubrimiento de información aplicados a los datos actuales que tienen almacenados.
En este artículo voy a explicarte en qué consiste este proceso, qué fases tiene y voy a darte una breve introducción a todas las tareas que se puede llevar a cabo, junto con las técnicas con las que se lleva a cabo el proceso.
¡Adelante!
Proceso de descubrimiento de información
El proceso de descubrimiento de conocimiento en bases de datos (Knowledge Discovery in Databases, KDD) puede definirse como el proceso no trivial de identificar patrones válidos, novedosos, potencialmente útiles y comprensibles a partir de los datos.
Los datos obtenidos mediante el proceso de descubrimiento de conocimiendo de una base de datos son los siguientes:
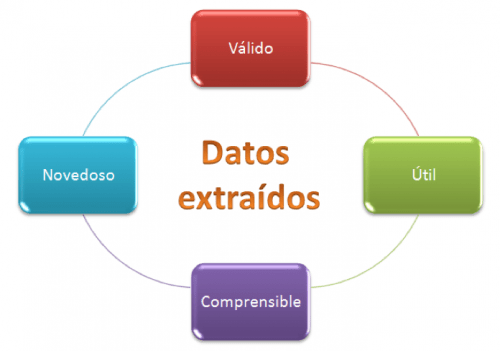
El conocimiento extraído debe ser conocimiento relevante que está oculto en la base de datos y que su extracción reporta beneficios, y obviamente, se trata de un conocimiento previamente desconocido.
El proceso KDD está compuesto por diferentes etapas que se realizan de forma secuencial e iterativamente, es por ello que es posible aplicar varias veces el proceso KDD hasta obtener el conocimiento que estamos buscando.

Las fases del proceso KDD se definen de la siguiente forma:
- Recopilación: Consiste en la integración de diferentes fuentes de datos en un mismo almacén de datos, data warehouse. En próximos artículos te explicaré en qué consiste un data warehouse.
- Selección, limpieza y transformación de datos: Los datos integrados deben de ser tratados antes de realizar el proceso de minería de datos. Debe realizarse una selección de aquellos datos que van a utilizarse, y sobre ese subconjunto de datos hay que realizar un proceso de limpieza y transformado para dejarlos en condiciones de ser tratados en fases posteriores. El objetivo de esta fase es obtener una vista minable para la fase siguiente.
- Minería de datos: Es considerada la fase más importante del proceso de KDD, se define como el proceso de exploración y análisis, por medios automáticos o semiautomáticos, de los datos existentes en la vista minable obtenida en la fase anterior con el fin de descubrir patrones/modelos significativos y reglas. El resultado de la fase son los patrones/modelos de esa minería.
- Interpretación y evaluación de modelos: El primer paso de esta fase es la evaluación de los patrones y modelos obtenidos, ya que, antes de ser interpretados para la obtención de conocimiento, debe de comprobarse que tienen la calidad suficiente para poder realizar la interpretación.
En los próximos apartados vas a adentrarte en la fase de minería de datos, ¡voy a explicarte diferentes tareas y técnicas que se pueden llevan a cabo en ella!
Tareas en minería de datos
Es importante diferenciar entre las diferentes tareas dentro del proceso KDD y los propios métodos existentes en minería de datos. La minería de datos es una de las fases del proceso KDD.
Los métodos de minería de datos pueden ser predictivos, es decir, tratan problemas y tareas en los que hay que predecir uno o más valores para uno o más ejemplos, o pueden ser descriptivos, buscan describir datos existentes.
Los métodos predictivos se clasifican en:
- Clasificación
- Categorización
- Preferencias
- Regresión
Los métodos descriptivos se clasifican en:
- Agrupamiento
- Correlaciones y factorizaciones
- Asociación
- Detección de valores e instancias anómalas
Para llevar a cabo la minería de datos se pueden llevar a cabo diferentes técnicas, entre las que destacan:
- Redes Neuronales
- Árboles de Decisión
- Algoritmos Genéticos
Métodos predictivos
Clasificación
Es uno de los métodos más utilizados en minería de datos. Su objetivo es predecir un nuevo valor basándose en una función de clasificación aprendida basándose en los datos disponibles.
Dentro de la clasificación se puede encontrar la clasificación suave, que consiste en la utilización de funciones auxiliares que indican el grado de certeza de la clasificación. Al conjunto de funciones utilizadas para predecir valores se les llama estimadores de probabilidad.
Categorización
En este método se aprende una correspondencia, es decir, para cada entrada al método existen una o más correspondencias para poder determinar la salida.
Al igual que en el método de clasificación, aquí existe una categorización suave, que utiliza correspondencias auxiliares para poder determinar la certeza de la categorización. Las correspondencias se llaman estimadores de probabilidad.
Preferencias
El método consiste en la obtención de una lista de preferencias de unos datos a partir de datos previamente ordenados.
El funcionamiento es similar a la clasificación y categorización, pero la definición es más compleja ya que hay que definir secuencia de elementos.
Regresión
La regresión es un método muy parecido a la clasificación; cada entrada se corresponde con un único valor de salida y se debe aprender la función capaz de predecir nuevos datos.
La diferencia con la clasificación radica en que los datos de salida únicamente son numéricos y son representados normalmente por gráficas. La regresión suele denominarse estimación cuando hablamos de valores futuros e interpolación cuando hablamos de valores intermedios.
Métodos descriptivos
Agrupamiento
El método de agrupamiento tiene como objetivo el obtener conjuntos de elementos similares entre sí, es decir, formar grupos de elementos lo más homogéneos posible dentro del grupo y heterogéneos respecto al resto de grupos.
En este método no se aprende a qué grupo pertenece una entrada, sino que se aprende y crea los grupos a partir del propio proceso de aprendizaje.
En la agrupación también existen los conceptos de agrupación suave y estimadores de probabilidad.
Correlaciones
Este método tiene el objetivo de saber si dos o más atributos están relacionados de algún modo, partiendo de un conjunto de atributos de un elemento.
Únicamente se limita a atributos numéricos y únicamente determina la relación entre dos elementos, nunca causalidad; resumiendo, son bidireccionales y no orientados.
Asociación
Es un método similar a correlación, pero utilizando atributos nominales. Se utilizan reglas de asociación. Las reglas son una de las tareas principales de la minería de datos y se aplican comúnmente a bases de datos.
Las asociaciones entre atributos pueden ser unidireccional y orientada o bidireccional; incluyéndose, cuando se considere oportuno, en estas últimas, las dependencias funcionales.
Detección de valores atípicos
En el proceso de minería de datos es normal encontrar valores que no son similares a ninguna de las demás instancias; en eso consiste este método. Es utilizado para detectar fraudes, fallos…
Técnicas de minería de datos
Redes neuronales
Las redes neuronales son una herramienta utilizada para análisis estadísticos que permite la construcción de un modelo de comportamiento a partir de unos datos de entrada. La red neuronal va aprendiendo desde cero a partir de los datos de entrada, para después transformarse en un modelo capaz de rendir cuenta del comportamiento observado en función de los datos de entrada. Es decir, la red neuronal, una vez construida, constituye un verdadero modelo que actúa en función de lo que percibe.
En la imagen siguiente podemos observar el funcionamiento de una red neuronal:

Las redes neuronales están preparadas, según el aprendizaje que ya tenga adquirido, para responder a cualquier tipo de dato de entrada.
Se trata de una técnica que está tomando mucha fuerza en el presente, ya que, las capacidades de cálculo han aumentado mucho y ha permitido que puedan aprender más rápidamente y con mayores volúmenes de datos.
Árboles de decisión
Los árboles de decisión son estructuras de datos basadas en toma de decisiones en forma de árbol. Cada árbol representa un conjunto de decisiones y van guiando el proceso de aprendizaje en función de la decisión tomada; las decisiones generan reglas para la clasificación de los datos.
A continuación puede verse un ejemplo de árbol de decisión:

Algoritmos genéticos
Los algoritmos genéticos permiten obtener soluciones a un problema que no tiene ningún método de resolución descrito de forma precisa, o cuya solución exacta, si es conocida, es demasiado complicada para ser calculada en un tiempo aceptable.
Los algoritmos genéticos siguen el siguiente pseudocódigo:

Estos algoritmos funcionan debido a que, a medida que se va ejecutando el proceso van sobreviviendo únicamente los miembros de la población «más fuertes».
Resumen y conclusiones
Con el artículo has empezado a adentrarte en el mundo de la minería de datos, con unos conceptos básicos que estoy seguro harán que te pique la curiosidad en seguir adentrándote en este maravilloso y novedoso mundo que será un valor al alza en los futuros procesos empresariales ligados a desarrollo de software de las grandes compañías.
Estate atent@ a futuros artículos, ya que voy a adentrarme en cada una de las diferentes tareas y técnicas ligadas a la minería de datos para que puedas tener un conocimiento más amplio de cada una de ellas y puedas aplicarlas en tus desarrollos.
Además, en próximos artículos también te explicaré qué es un data warehouse y cómo construir uno. ¡No te lo pierdas!